
What does it actually mean for a site to be considered down?
Often that depends on whom you ask.
For a website to be considered down, it may mean a number of different things:
- The website is completely unavailable.
- The website is online but unusably slow.
- The website is giving error messages for certain users or locations.
- The website is working for most visitors, but some simply can’t log in to their CMS, for example, to create, edit, or publish content.
No matter the cause or degree, the impact of website downtime can be serious, from lost ecommerce orders and frustrated users to weakened customer trust.
In the third of our Avoiding CMS Disaster series, we explore classic root causes of website downtime and the role continuous monitoring and other factors play in avoiding that.
First, the role continuous monitoring plays
We monitor different aspects of a website, so we can tell when something is not working correctly at any of the different layers that make up our fully managed WordPress VIP platform. Those layers include:
- Network connectivity
- Load Balancers
- Web servers
- Object caching (Memcached)
- Databases
- Elasticsearch
- Files Service (CDN)
We try to spot issues early so that we can anticipate future issues that might affect website stability. Cross-referencing logs from different system components allows us to review periods when a website was reported unstable. Because a combination of factors rather than a single issue might be responsible for downtime, we employ a number of tools to compare data across both systems and applications.
In most cases, website instability is a result of application code, i.e., custom or third-party WordPress theme and plugin code. Here are a few things we look for when investigating an unstable site, and how to mitigate each.
Not enough caching
The most important thing you can do to ensure a site is performant and stable is to make sure any full page that can be cached, is cached. Uncached pages need to be built on the server each time they are requested, which is a slower process and more prone to errors.
The WordPress VIP answer:
WordPress VIP Platform provides powerful page caching via a global network of edge cache servers, each used to store and serve content closest to an end user. The response time from an edge cache server is almost always a magnitude faster than anything that bypasses page caching and hits the origin servers.
Caching challenges
Because they demand a personalized, fully interactive experience, some sites, particularly ecommerce ones, simply can’t be cached at the page-cache level.
Often a compromise can be found whereby a static page is served by edge cache, with dynamic features (e.g., logged-in status, shopping carts) added via JavaScript. Asynchronous requests from JavaScript can then be used to communicate with a WordPress REST API endpoint designed with a much lower overhead than a full page load.
Alternatively, this is where object caching comes into play. The page can remain dynamic but parts of the page and any data used in it can be stored and retrieved in object cache to avoid needing to query the database.
The WordPress VIP answer:
Each WordPress VIP application environment has its own dedicated Memcached cluster, which stores object cache data in memory for lightning quick and efficient retrieval.
Untested code deployments
This is another common culprit of website downtime and pretty easy to diagnose, based on pure cause and effect.
If your website has just deployed untested code, leading to immediate site issues, there’s your likely cause. If you can, revert the suspect code to the previous version ASAP.
The best thing to do to avoid this situation? Thoroughly test every piece of code on a separate development or staging environment before releasing to production.
The WordPress VIP answer:
Because all our site deployments are via GitHub, WordPress VIP customers can easily revert code themselves, without losing any new code changes, which remain stored safely in the GitHub revision history. Optionally, in emergency situations, we can rollback a customer’s website to a previous deployment on their behalf, independently from GitHub.
Regarding environments, all applications hosted on our fully managed service can have a separate development or staging environment. Syncing data there from production is easy, letting you test code against the same amount and same type of data as on your production website.
PHP errors
WordPress uses PHP code on the server. A PHP error might be “fatal,” meaning that once the error occurs, the web page, script, or command will stop running. These will almost always surface as visible errors somewhere, and will be recorded in the PHP logs.
Note: Some PHP warnings in PHP 7 become fatal errors in PHP 8, so it’s important to take these errors seriously.
The WordPress VIP answer (plus helpful advice):
Our platform automatically logs all PHP errors, making them available to WordPress VIP customers in their dashboard and to our engineers.
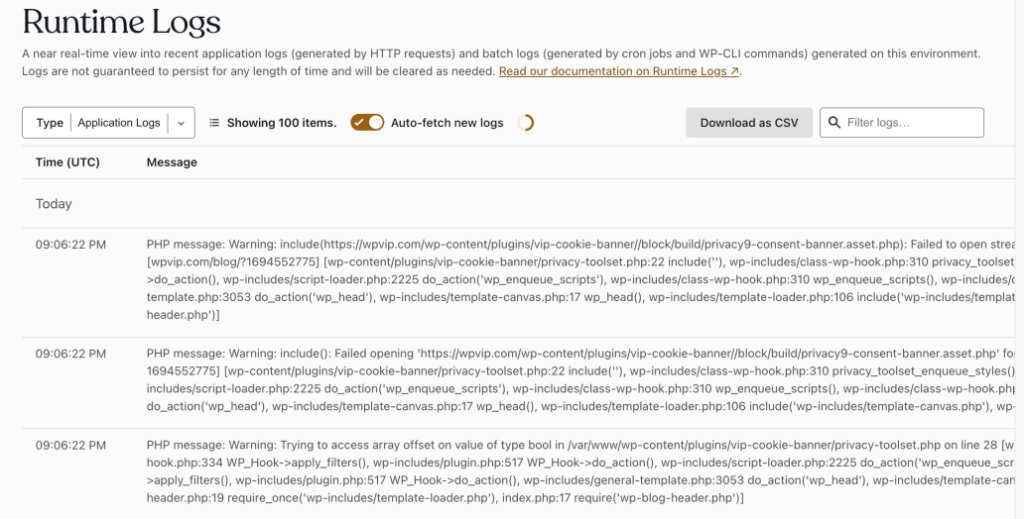
Pro tip: Address and fix all PHP errors—even if a site appears to be working fine. Routinely, we see logs full of PHP errors, even fatal ones, on a site that appears stable. However, that doesn’t necessarily mean the site is working correctly. Keeping PHP logs clear by addressing minor errors and warnings makes it easier to find more serious errors during debugging.
Slow MySQL database queries
Every WordPress website uses a database to store website content and configuration data. Database queries fetch that content data for web pages, but sometimes those queries are written inefficiently. They may work fine for sites with only a few hundred pages, but stall when handling large amounts of data (some websites on our platform have millions of stored records).
A slow query ties up database resources, potentially impacting site stability—not just for the page, script, or command running the SQL, but across the whole application. Sites often struggle because single or multiple database queries are slow, e.g., any query that takes longer than 0.75 seconds to execute.
The WordPress VIP answer:
WordPress VIP helps mitigate database bottlenecks by providing each application with a dedicated database cluster featuring a primary database, where all database write queries occur, and one or more read-only replica databases. This increases the number of simultaneous database queries that can take place, spreading the resource load when a site is under pressure. That said, slow database queries can’t always be resolved simply by adding additional database resources. That’s why we advise customers to monitor slow database queries by using Query Monitor and New Relic (provided by our platform). These highlight where queries originate in the database, so your development team can refactor them to optimize performance.
Finally, our Support Engineers can also help your team find and analyze these queries, and suggest ways to improve them for speed and efficiency.

Excessive database writes
Sometimes a feature, such as custom logging or tracking code, updates the database on every request. This can lead to instability for two reasons:
- Foregoing database replicas: All write queries are directed to the primary database; subsequent database queries for the same table (or tables) in the same page request will also be directed there. By not taking advantage of database replicas, this limits the scalability of the site.
- Bypassing page caching: For a database write to happen on every page request, page caching must be bypassed. But doing so means the first (and best) line of defense has been compromised.
The WordPress VIP answer:
In these circumstances, we advise refactoring the feature. For example, content analytics is usually best delegated to an external service that uses a snippet of JavaScript in the page rather than server-side code, which doesn’t work well with caching and may result in excessive database writes.
Other known causes of downtime and how to avoid them
Plugins
There are thousands of popular, helpful third-party plugins in the WordPress ecosystem that provide fantastic features and functionality. Some, though, have challenges scaling, potentially leading to downtime issues when added to a website with tons of content and traffic.
The WordPress VIP answer:
As good ecosystem stewards, we regularly reach out to vendors with suggestions to make their plugins perform better in high-traffic environments. We can also suggest alternative plugins that have been tried and tested at scale on our platform.
Custom logging
Custom logging is a powerful debugging tool, often the only viable method to track down a bug or issue that seems to happen only on a production site. On numerous occasions, however, we’ve seen custom logging built in PHP on a high-traffic site slow down things or put a site in danger of downtime through excessive database writes.
The WordPress VIP answer:
For customers, we provide access to standard PHP logs in the Health panel of the WordPress VIP Application Dashboard. There they can log custom errors (and also to New Relic), which will not negatively impact the database.
Remote API calls
Some websites take advantage of server-side REST API calls to other applications or services. These are pretty fast under normal circumstances, but sometimes the underlying application code leads to a slow response, times out, or throws an error.
The WordPress VIP answer:
To minimize these issues, we advise “defensive coding.” It depends on the purpose of the remote call, but often when a remote request fails, it’s possible to fall back on a cached response from a previous request—or at least “handle the error gracefully,” so that the rest of the page can still load. We provide a number of helper functions to handle these scenarios. Keeping a low timeout also means PHP resources are freed up quicker if the remote API is not responding.
Read more in our Avoiding CMS Disaster series
When your business is on the line, you can’t afford to send new business elsewhere and tarnish your brand by having your content management system (CMS) deliver a poor digital experience. In How to Improve Website Performance, we diagnose five common slowdown culprits and how to turbocharge things using an agile CMS.
High-traffic days ought to be cause for celebration, not a nightmare for engineers on their collective back foot trying to keep a site and applications up and humming to handle the load—and your reputation intact. In Scaling WordPress for High Traffic, we explore four approaches to enabling a WordPress website to handle those traffic tidal waves.
Become an enterprise-level WordPress developer with VIP Learn
Over 40% of the web runs on WordPress, including some of the world’s largest organizations. Learn enterprise-level WordPress development skills from the folks at WordPress VIP for free and on your schedule.